Input: Thank You project Phase 1: Part 1
Summary
Beginning
When users click on "Submit feedback..." in Firefox, they end up on our Input site where they can let us know whether they're happy or sad about Firefox and why. This data gets collected and we analyze it in aggregate looking for trends and correlations between sentiment and subject matter, releases, events, etc. It's one of the many ways that users directly affect the development of Firefox.
One of the things that's always bugged me about this process is that some number of users are leaving feedback about issues they have with Firefox that aren't problems with the product, but rather something else or are known issues with the product that have workarounds. It bugs me because users go out of their way to leave us this kind of feedback and then they get a Thank You page that isn't remotely helpful for them.
I've been thinking about this problem since the beginning of 2014, but hadn't had a chance to really get into it until the end of 2014 when I wrote up a project plan and some bugs.
In the first quarter of 2015, Adam worked on this project with me as part of the Outreachy program. I took the work that he did and finished it up in the second quarter of 2015.
Surprise ending!
The code has been out there for a little under a month now and early analysis suggests SUCCESS!
But keep reading for the riveting middle!
This blog post is a write-up for the Thank You project phase 1. It's long because I wanted to go through the entire project beginning to end as a case study.
What are we trying to do here?
In the last week there were 1785 feedback submissions that were:
Sad
for the Firefox product
in the en-US locale
(See for yourself. [1])
A glance at the first page of results on Input shows some feedback talking about crashes, CPU usage issues, memory usage issues and general slowness. Some of these are known issues. Some of these are issues and there are known workarounds. Definitely some malware issues.
I claim this is a pretty typical week and that we regularly get feedback like this.
Thus my hypothesis:
Some sad feedback on Input is about known solvable problems and Input can help those users.
I decided a good first pass at this problem would be to take the feedback data the user submitted and run a search on SUMO. SUMO would return a list of relevant knowledge base articles. Input would list these as links in a "suggestions" section on the Thank You page. The user can read through them and click on the ones that are appealing.
Running it by others
I ran my idea by User Advocacy and the SUMO engineers to see what they thought. Would searching SUMO return articles relevant enough to the feedback to be useful? Would relevant kb articles help these users?
User Advocacy thought my hypothesis sounded plausible and was worth pursuing.
The SUMO engineers thought search should return results that are helpful and if not, we could tune them.
At this point, I wrote up a project page and a tracker bug.
project page: https://wiki.mozilla.org/Firefox/Input/Thank_you_page
[bug 1007840] [tracker] make thank you page for sad feedback helpful (phase 1)
Throwing together a prototype
Before we got too far into this, I wanted to see whether SUMO could provide relevant suggestions for user feedback.
Adam and I wrote a command line script that pulled down feedback from Input using the public API and then run a search on SUMO with that feedback to see what it suggested.
SUMO actually has several API endpoints that return knowledge base articles. We decided to look at all of them.
Adam looked at a couple hundred pieces of feedback and the suggestions that SUMO gave. He marked which results were probably relevant and then we figured out which SUMO API endpoint yielded the best results.
The SUMO search suggest API endpoint at /api/2/search/suggest/
(aka Francis) gave relevant kb articles for 50% of the feedback we
tested. That seemed pretty good.
It's worth noting that we weren't aiming for 100% because not all feedback is about problems with Firefox and some of it uses terms or language that won't match our domain terms/language. 50% seemed like a good start and worth continuing this project.
[bug 1124412] [research] evaluate SUMO search APIs for best results given a piece of feedback
Making infrastructure changes
When we finish this project, we want to be able to turn it on and shut it off if there are problems. Input uses django-waffle for flags and switches which is perfect for this.
Adam create a flag for turning this feature on and off. Adam also made the changes to the view and template code with a code path that kicks off when the flag is on.
[bug 1116523] add new response id to session
[bug 1116838] add waffle flag for thank you page
[bug 1116848] change thank you page view to allow for thank you page variations
How to measure success
I thought about this and wrote up a first pass of questions I thought really elucidate success here. They didn't feel quite right, but they seemed like they were in the right direction.
And then I talked with Gregg
Gregg Lind [2] offered to look them over. We had a long talk and worked out a better set of questions that not only help us understand whether this project is successful or not but also help us later on when we want to determine whether one algorithm for determining suggested links is better or worse than another.
We came up with the following questions:
-
Are we helping users?
This is essentially a question of engagement. We know we're helping users if they're clicking on the suggested links we've provided. Thus we can use an equation like this:
clicked on at least one link ---------------------------- total people offered a suggestion
In other words, if someone got suggestions and clicked on a link--that's success.
We had no idea where the bar for success vs. failure is here, but Gregg thought 20% engagement seemed like a good number to shoot for initially.
If we end up with like 5% engagement, maybe the hypothesis is wrong and either we're trying to solve a problem that doesn't exist or the heuristics for generating suggestions stink.
-
Are the heuristics for generating suggestions good?
There's a complication here in that the data at the end of the suggested link might be right on, but the user might not click on the link because all they see is the summary and title.
Ergo, it's not good enough to have good suggested links--those links have to be attractive, too.
This this becomes more of a "How attractive are the suggested links?" questions.
One thing we decided here is that we need an "everything sucks" option. So in addition to showing suggested links to relevant kb articles, we're going to have a "None of these helped" link that's always the last one in the set of links.
With that, we end up with the following two equations:
clicked on a suggested link --------------------------------- total people offered a suggestion
vs.:
clicked on "None of these helped" link -------------------------------------- total people offered a suggestion
These two equations help us clarify the results of the first question.
While discussing what data we needed, we also discussed how we can collect the required data.
[bug 1133774] [research] figure out how to track performance of new thank you page
How to gather data
Tracking the data was tricky. It's not good enough to just track suggestions and clicks. We needed to know whether a user who saw one set of suggestions clicked on a link in that set. Thus we needed to maintain some kind of session between the two events.
All feedback responses in Input have a response id. This id uniquely identifies that response. Further, a set of suggestions will be tied to a specific response.
Given that, we can use the response id when logging the suggestions event as well as any click events.
And then I talked with Lonnen
I talked with Chris Lonnen [3] who's the Data Steward for Input. We want to collect the data we need to understand the success of the project, but we don't want to do it in a way that violates people's expectations of privacy and data collection.
Instead of keeping all the data on Input for this, we decided to do server-side pings to Google Analytics. Since we're using response ids and all the events originate from Input, there's nothing to correlate the data with anything else on the Internet. This also allows us to use Google Analytics event flows to do the calculations.
This requires me to also write a URL redirector.
[bug 1133774] [research] figure out how to track performance of new thank you page
Architect and implement
At this point, I've figured out enough of the requirements and how the pieces need to fit together to start architecting things.
At the end of April, I saw Lars present The Well Tempered API [4]. Since then, I've been pushing to generalize things into frameworks.
In that context, I decided to write a suggestion framework and a redirector framework. The Thank You page suggestions from SUMO get implemented as a single suggestion provider. Later on, we can add other providers that look at feedback or what's trending in Bugzilla or the phase of the moon [5] and generate suggested links for the Thank You page based on other heuristics and criteria. Since suggested links are tied to redirections, it seemed to make sense to also have a framework for redirection.
I built the suggest and redirector frameworks, then implemented the SUMO Suggest suggester and redirector. I wrote tests for all the bits involved.
[bug 1161144] [tracker] suggest framework
project plan: https://wiki.mozilla.org/Firefox/Input/Suggest
[bug 1169261] implement suggestion link redirector
[bug 1133769] implement sumo search code
There might have been a few other bugs involved, too.
Mockups
The Input Thank You page is responsive and has modes for "phone", "tablet" and "desktop" based on viewport width. The changes we want to make needed to work in all three of those contexts.
Just before the Outreachy program ended, Adam did a set of mockups for what the Thank You page would look like with suggestions.
And then we talked with Matt and Verdi
We solicited thoughts from User Advocacy and also Michael Verdi. I worked through the comments from Matt and Verdi and came up with a new set of mockups.
Then Verdi threw together a mockup that really clicked for me in that it was clean and easy to understand in regards to the rest of the page. Some more back and forth about some of the language and then we ended up with mockups that I really liked and met the requirements I had set out.
[bug 1129615] mockups for thank you page for sad feedback
Some tricky things
When the user's browser submits the feedback form, the HTTP conversation goes like this:
client: Yo, here's some feedback.
server: Looks good. I will save the feedback to the db. It is saved. Now I'm going to redirect you to the Thank You page.
client: Oo--I love Thank You pages. Give me some of that, please!
server: Who are you again? Oh, I see your session id and in your session is the response id for the feedback you left. Let me fetch the feedback from the database and then run it through all the suggestion providers.
[some time passes]
Ok. Here's a Thank You page with suggestions!
There are two tricky parts here.
The first is that the client posts some feedback, then the server redirects the client to the Thank You page URL. Then the client requests the Thank You page. We have to pass the response id along otherwise the server has no idea which feedback the client left when it's trying to handle the Thank You page request.
We could pass it along in the query string, but then it's obvious from the URL what's going on and it's possible for someone to just go through all the response ids and get suggestions which could have performance consequences with the server. Further, we don't show all feedback on the front page dashboard, so this would make it possible someone could learn about feedback they wouldn't otherwise be privy to based on what kb articles were suggested.
We could put it in a cookie where it's less obvious, but similarly to the query string problem, it's possible for someone to just iterate through response ids [6].
What I decided to do was put it in the session. Django saves the session id in the cookie and the data for the session in the database. It's much harder for someone to hijack a Django session to get the response id. I made sure the code handled the cases where the request has no session cookie, the session is invalid, the session has expired and similar possibilities. In this way, we can maintain continuity between the events without creating other problems.
The second problem is the "[some time passes]" part. There really isn't a good way to make the work of providing suggestions asynchronous, so we have to make sure the work done during the HTTP-request cycle is the minimal amount of work, anything that's cacheable is cached and anything we can pre-compute is pre-computed.
The second problem also manifests itself if the user requests the Thank You page again. Maybe they hit the back button in their browser. Maybe for some reason they bookmark the page. Maybe Flash crashes their browser. Maybe their cat jumps up on the keyboard hitting Ctrl-W. In these cases, it'd be super if we didn't redo all the work and instead just pulled it from cache.
I kept this issue in the back of my head when writing the code.
Throwing it all together
I implemented the mockups and the rest of the bits.
On June 10th, I pushed it to -stage and -prod. It wasn't active, yet, since we hadn't enabled the waffle flag for everyone. However, if you knew the secret handshake, you could see the results. I asked some folks to test it out. It looked great and worked great.
We made it live and within 10 minutes saw a few events show up in Google Analytics.
CODE SHIPPED!
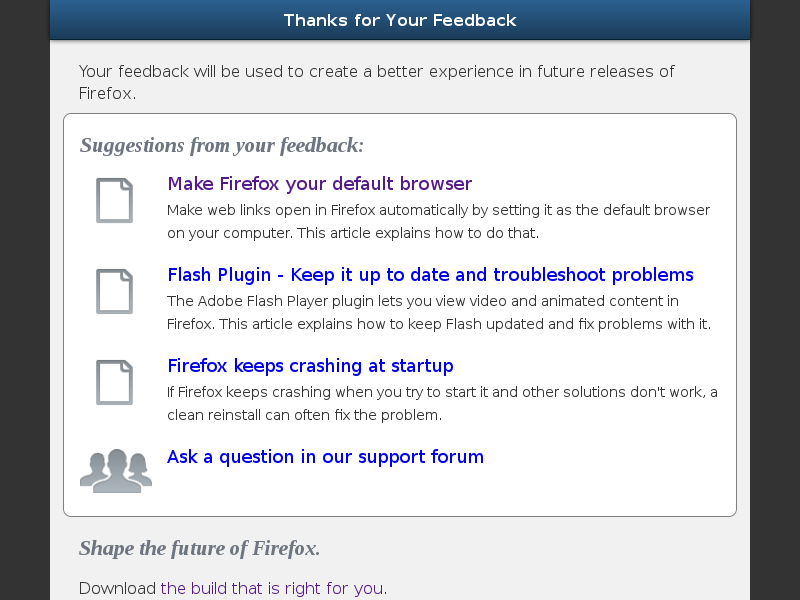
Thank You page with suggestions.
But ... is it good enough to stick around?
Analysis
How did we do? Did we succeed? Does it need improvement? Is it good as it stands? Should we declare epic fail, rip it out and change careers?
Let's look at the Event Flow for the sumo_suggest1 event in Google
Analytics for the last week:
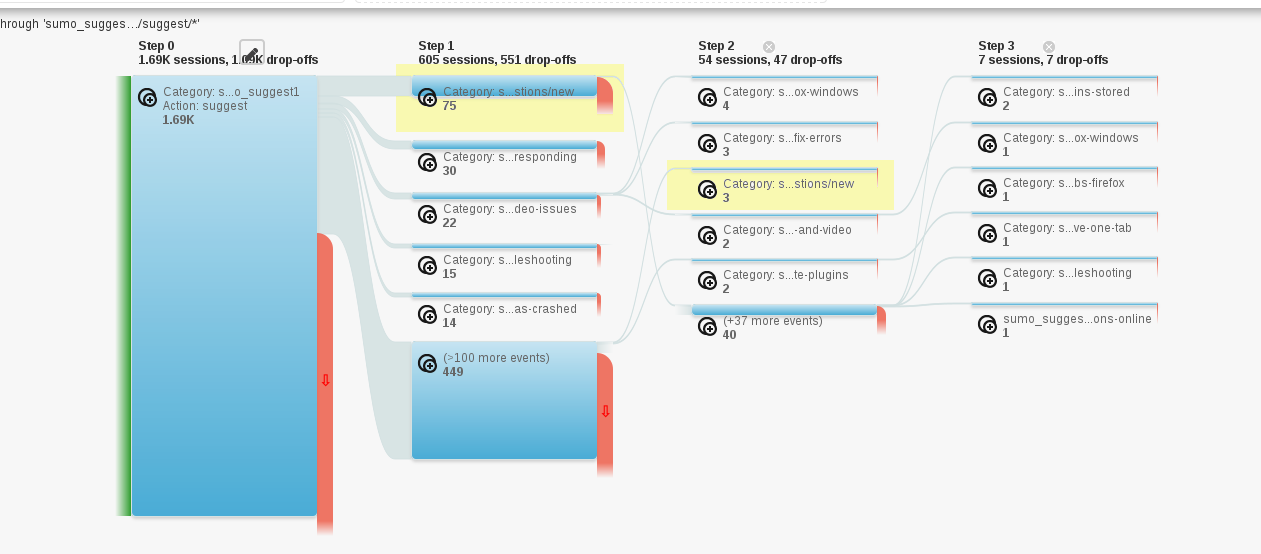
Event flow for sumo_suggest1 events in Google Analytics
The links are hard to read. The ones in yellow boxes are the "None of these helped" links.
In the last week, Input served suggestions to 1.69K people.
Of those, 605 of them clicked on something. 75 clicked on the "Ask a question in our support forum" link.
54 clicked on a second link. 3 clicked on the "Ask a question in our support forum" link.
7 clicked on a third link.
Going back to our equations, we get:
Total engagement:
605 / 1690 = 35.7% people clicked on something
That's well north of 20%, so I think this is a success and that we are solving a real problem here.
Success of the suggestions heuristics:
530 / 1690 = 31.3% people clicked on a suggested kb link
vs.:
75 / 1690 = 4.4% people clicked on "Ask a question in our support forum"
31.3% vs. 4.4% suggests our suggestion heuristic is decent--definitely not completely terrible. I suspect we can do better than that. Not many people choose a second link to click on, so it seems like of the three suggested kb links only one is attractive. Is it the case that the SUMO kb is such that there's only on attractive link? Is it the case that the heuristics we're using aren't good enough? Is it the case that the user clicks on one link out of curiosity, discovers themselves on SUMO where they didn't want to be and then doesn't click on any others?
It would be good to do another round of qualitative analysis to determine how much better we can get since we know that not all users' feedback will have relevant kb articles.
This is just looking at the last week of data. Some weeks we'll do much much better and some weeks we'll do less well depending on what's going on with the Internet, Firefox releases, etc. SUMO knowledge base content changes over time, too. It probably makes sense to do this analysis for every week over the course of a couple of months to see how well we do over time.
Another thing that came out of this is that I have a top 10 list of kb articles that users think are relevant to their feedback. That'll probably be interesting to the SUMO folks.
What's next?
We definitely want to finish off phase 1 by fixing the code so we can turn on and off suggestions on a product-by-product basis. Further, we need to make the necessary changes to make it work across locales.
In looking over the draft of this paper, Mike and I tossed around some additional experiments we could do here.
-
Hypothesis:
Making the top-most link more attractive will increase engagement.
The thinking here being that users are looking at the first link the hardest and then their eyes glaze over for links 2 and 3.
-
Hypothesis:
Reducing suggested links to only the most relevant links increases engagement.
There are some technical bits here. We currently get back 3 relevant kb articles from SUMO. We get the scores back, too, but if you do two different searches, you get results with scores that are in two completely different ranges. So we can't apply a single threshold to all searches to filter out irrelevant search results. Because of that, we just show the top 3.
We could, however, look at the top result and its score and then show that link and all the links with scores that are within, say, 20% of that figuring they're all "close" results and thus "relevant".
Maybe reducing results in this way makes it more likely users find the links attractive.
-
Hypothesis:
Increasing the
minimum_should_matchfor the SUMO suggest search will produce results that increase engagement.This is even more technical. When Input uses the SUMO suggest API endpoint, what's going on is that SUMO forms an Elasticsearch search and then returns the results. That Elasticsearch search does a
matchand amatch_phraseusing the defaults [7].If we specified a higher
minimum_should_match, we might increase the quality of the top 3 search results [8].
Additionally, I want to build some new suggestion providers to solve some other problems. In 2015q3, I'm working on a trigger suggestion provider that yields suggestions based on certain trigger criteria.
[bug 1175123] [tracker] keyword trigger suggestions provider
project page: https://wiki.mozilla.org/Firefox/Input/Keyword_suggester
Final thoughts
Sometimes it's good to be rigorous.
I do a lot of development where it makes no sense at all to go through this kind of rigorous project life cycle. That's less a statement about general development and more a statement of the kinds of things I tend to work on. When I do work on projects like this one, this kind of rigor almost always results in less total work done.
Other people rock. Ask early. Ask often.
Bouncing things off of other people is almost always a huge win. People have different perspectives and experiences they pull from.
Keep it small and focused until the hypothesis is proven.
Being able to keep the project small is a skill one has to develop. There were many points over this project where we could have changed the goal or increased the scope. I still think some of those things are really good ideas. Every single one of them would have involved more time and work and until we finished this phase, we didn't even know if the hypothesis was vaguely true.
Do a write-up/blog post.
I've done a few other projects over the last year and I forget the details now. I wish I had done more write-ups.
Me.
I did a lot of work here. Also, this is an idea I had in the beginning and carried through to fruition. Helping 600 people a week isn't going to solve world peace, but it's definitely helping some percentage of those people every week.
Future phases will increase that number.
Plus it established a framework for other things to use.
This is a good change that makes a difference.
And you.
I had a lot of critical help here:
Ricky, Mike and Rehan--my fellow SUMO engineers helped with peer review, bouncing ideas, honing the SUMO suggest API, etc.
Matt, Tyler, Cheng, Ilana, Gregg and Robert for bouncing ideas off of, mockup reviews and clarifying the important questions and how to answer them with data.
Lonnen for being a superb manager for me and also figuring out the data collection component.
Verdi whose mockup was fantastic.
Adam for all his work and thoughts on this project.
All the people who listened to me kvetch about this problem for the last year and a half--I will kvetch no more!
That's it!